1.1 强化学习的概念与分类
强化学习是一种机器学习方法,通过与环境的交互来训练智能体,使其在不 同状态下采取能够最大化累积奖励的行动。其目标是通过试错学习(trial-anderror)找到最优策略,使得在长时间内累积的奖励最大化。在强化学习中,智能 体(agent)通过与环境的互动不断学习,通过奖励和惩罚来调整其策略,以便 在长期内获得最大回报。在股票市场中,强化学习可以通过市场状态的输入,不 断调整交易策略,最大化长期的投资回报。
除此之外,强化学习的数据输入不是固定的。在强化学习中,数据是在智能 体与环境交互的过程中得到的。强化学习是在线训练的,如果智能体不采取某个 决策动作,那么该动作对应的数据就永远无法被观测到,所以当前智能体的训练 数据来自之前智能体的决策结果。因此,智能体的策略不同,与环境交互所产生 的数据分布就不同。
强化学习有很多类别,主要分为依赖模型的强化学习(如 alphago)与无模 型强化学习。多数强化学习模型并无依赖模型,即不尝试理解或预测环境的动态 (如状态转移概率和奖励结构),而是直接从与环境的交互中学习如何行动。最 常见的 q 学习及其衍生算法都属于无模型的强化学习。
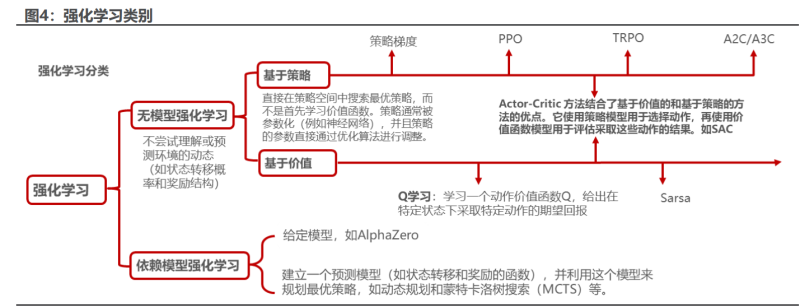
本篇研究中我们用到了结合基于价值与基于策略强化学习的结合,即演员评论家框架(actor-critic)。这类方法结合了价值模型和策略模型的方法,利用 价值函数来评估策略的好坏,并根据这个评估来更新策略。actor-critic 是囊括 一系列算法的整体架构,目前很多高效的前沿算法都属于 actor-critic 算法;需 要明确的是,actor-critic 算法本质上是基于策略的算法,因为这一系列算法的 目标都是优化一个带参数的策略,只是会额外学习价值函数,从而帮助策略函数 更好地学习。
1.2 强化学习在金融领域中的应用
在金融领域中,强化学习被大量应用于股票交易决策制定中。在强化学习进 行交易决策的框架中,主要可以在以下几个方面进行不同选择: 状态输入:当前市场环境。如过去一段时间的股票量价信息,当前市场风 格,基本面等;或者深度学习输出的对于股票收益的预测状态。 奖励函数:交易后的累计奖励,即组合净值,超额净值,经过风险调整后 的累计收益等等。模型算法及结构:q 学习,深度 q 网络(dqn),策略梯度,深度确定性 策略(ddpg),软演员-评论家(sac)等强化学习算法来训练智能体, 使其学会在不同市场状态下采取最优的交易动作。同时,在强化学习中包 含深度神经网络的部分,也可选取不同的神经网络模型结构。 在金融领域中,已有许多尝试使用强化学习(rl)方法进行交易决策的论文。 这些论文主要在以上三点进行了创新。对于输入状态的定义,yueyang zhong 等人在 2020 年 ijcai 上发表的论文 data-driven market-making via modelfree learning 中,作者用高频订单数据作为 q 学习的输入状态,以实现高频交 易决策,取得了远好于基准的表现;yuh-jong hu 等人用 gru 预测股票收益表 示作为市场状态,并且在奖励函数中加入了风险调整;在模型算法及结构上的创 新较多,如 suri 等人引入了分层结构的强化学习,最终较基线模型提升了交易胜 率。
1.3 软演员-评论家(sac)算法
本篇研究中用到了 sac 强化学习算法,sac(soft actor-critic)算法是 一种基于 actor-critic 框架的深度强化学习方法。相比于传统 ac 框架,sac 采 用软更新(soft update)策略,即使用指数移动平均(ema)来更新目标 q 网 络参数,这种更新方式使得目标 q 网络的变化更加平滑,从而提高训练过程的稳 定性。
本篇研究我们参考了 siyu gao 等人在 2023 年 ijcai 上发表的论文 stockformer: learning hybrid trading machines with predictive coding,论文中作者采用 sac 强化学习作为基础框架,并采用类 transformer 模型的输出作为强化学习的输入状态。在第二部分中,我们将对本论文进行详细 介绍。
2.1 利用 transformer 构造市场状态
为了预定义 sac 强化学习输入的市场状态,作者利用 transformer 模型预 测股票收益与市场相关状态。transformer 模型已经被广泛应用于股票收益预测 并输出因子,最初由vaswani等人在2017年的论文《attention is all you need》 中提出,其核心特点是全面依赖于注意力机制,并行学习序列的不同子空间,这 种机制可以让模型从不同角度理解数据的同时,大大提高训练效率。除此之外, 模型中还加入了位置编码,使模型能够利用序列的顺序;加入前馈网络有助于进 一步转换注意力层的输出;加入残差连接帮助避免在深层网络中训练时的梯度消 失问题。
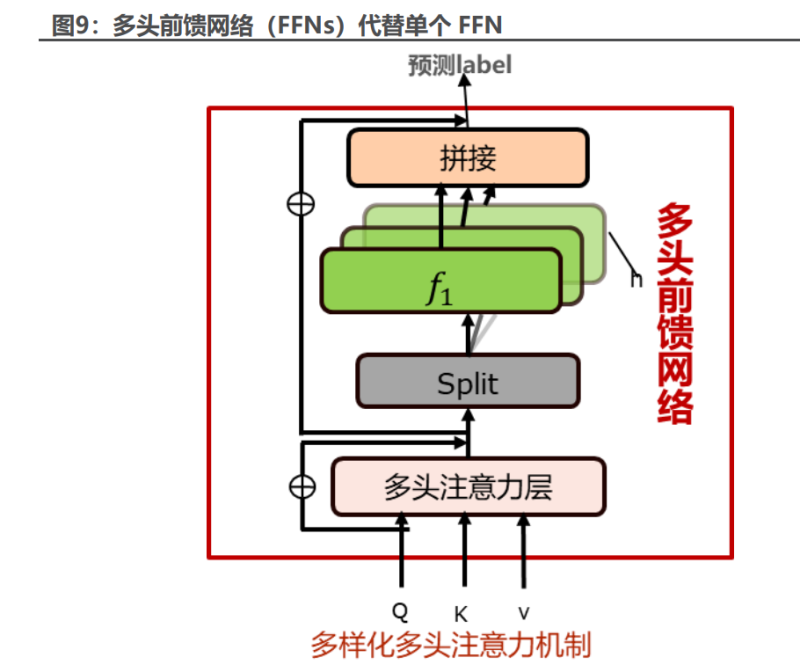
论文中,作者用到了 3 个 transformer 网络来构造市场状态的输入,分别学 习股票短期收益预测、股票中期收益预测与股票间相关性的潜在表示,这些表示 共同形成了下一个训练阶段用于 sac 强化学习投资策略的组合状态空间。在 transformer 的应用时,作者认为多支股票序列之间时间模式的多样性增加了从 原始数据中学习有效表示的难度。为了解决这一问题,作者用一组前馈网络 (forward feed network)而不是单个 ffn 来改造原始 transformer 中的多头 注意力块,其中每个 ffn 单独响应多头(multi-head)注意力层输出中的一个 头(head),在不改变整体参数数量的情况下,这种机制加强了多头注意力的原 始特征解耦能力,有助于在不同子空间中建模多样的时间模式。
作者用改进后的 transformer 进行了三次训练,分别预测市场相关状态, 股票收益短期预测状态与长期收益预测状态。第一个 transformer 将个股过去 252 天收盘价序列做协方差矩阵,与常见的 8 个日频技术因子拼接输入 transformer,transformer 分为编码器(encoder)与解码器(decoder)。在 第一个 transformer 中,应用编码器的输出作为股票市场相关状态的预测,即解 码器只起到了联合训练优化编码器的作用。 论文中选取了训练窗口期(10 年左右)内一直在沪深 300 内,且交易天数 在 98%以上的所有股票,数量为 88 只。协方差矩阵以股票维度的注意力替换了 原本的时序维度注意力,即相关状态的训练要求训练股票不变,在预测时也须预 测这 88 只股票,这也是论文中相关状态预测的局限性。
在第二和第三个 transformer 模型中,作者用了 10 个量价指标分别预测个 股 1 日收益与个股 5 日收益。10 个量价指标分别为:个股每日的开高低收价格, 成交量,与这 5 个指标与前一天的差分值,输入序列长度为 60 天。用 transformer 解码器输出作为股票预测状态,输入之后的 sac 强化学习部分。
2.2 stockformer 强化学习
stockformer 通过预测编码从时间序列数据中提取强化学习的潜在状态,然 后在组合状态空间中优化交易决策。前文中,我们从三个 transformer 分支中获 得三种类型的潜在表示:关系状态(?? ?????)、中期预测状态(?? ???? ,5 天收益预 测)和短期预测状态(?? ?ℎ??? ,1 天收益预测),随后通过多头注意力层将?? ????与 ?? ?ℎ???整合为未来状态( ?? ?????? ),最后再次通过多头注意力层将未来状态与 ?? ?????合并为 sac 的状态输入 st,输入 sac 强化学习。值得注意的是,关系状态 表示的方法并不唯一,在下文的模型改进中,我们将基本面信息,即风格因子的 邻接矩阵作为了相关状态的输入来源,解决了论文模型限定股票不变的局限性。
3.1 transformer 模型
首先,我们将 transformer 模型作为本篇研究中的基模型,与后续的 transformer sac 强化学习算法形成对照。
训 练 设 置 方 面 , 我 们 基 本 延 用 过 往 深 度 学 习 模 型 的 训 练 设 置 。 在 transformer 的 multi-head attention 机制中,head 数量取 10。我们取中证 1000 滚动成分股进行训练,在保证足够股票数量的同时,设置计算资源可以满 足的缓冲区,以让模型充分训练。此外,中证 1000 成分股权重分布较为均衡, 在强化学习中加入风险因子约束等传统风控方式会使得模型约束增加以导致一系 列潜在问题,在每只股票每天都有持仓的情况下,中证 1000 内选股可以使得股 票权重相对基准不会产生过大偏离。
在技术因子的选取上,我们采用民生金工因子库中对量价刻画较为有逻辑的 20 个技术因子,包含情绪,动量等因素,使得 transformer 模型有更多维度的输 入。
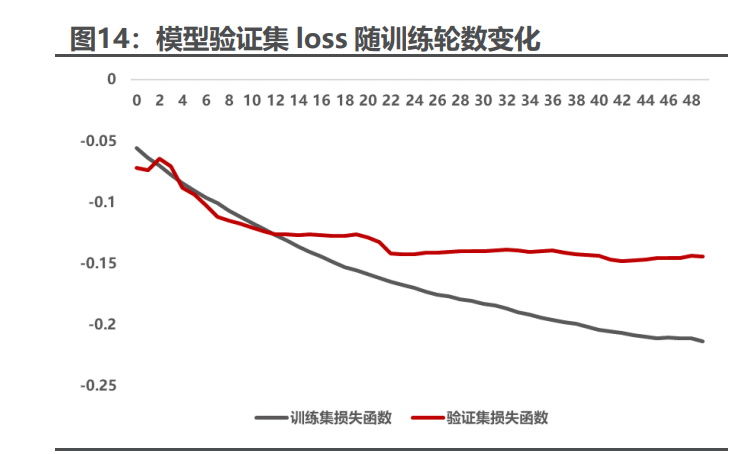
我们训练模型,将模型输出的收益排序作为选股因子 transformer,模型在 训练时 40 轮左右的验证集 ic 最高,损失函数变化趋势如下图。transformer 因 子的周度 rankic 均值 10.3%,icir1.02,表现尚可。因模型训练只在中证 1000 成分股内,可能影响模型预测表现。
我们用 transformer 因子构建指数增强策略。约束主动风格暴露在[-0.5, 0.5]之间,并约束行业暴露在[-0.1, 0.1]之间,个股偏离[20%, 500%] 。在限制个股偏离时,我们要求每只股票的权重在基准权重的 1/5 到 5 倍之间,目的是为了 更好地对比后续的强化学习,每支股票都有持仓。回测时,采用每周最后一个交 易日的因子即预测值,每周第一个交易日调仓,取每周一 vwap 价格作为执行价, 交易费用取双边千分之三,回测窗口为 2019 年至 2024 年 5 月 31 日。
模型在中证 1000 内年化收益 17.2%,超额收益 13.8%,信息比率 2.36,表 现稳定。策略分年超额收益比较均衡,今年截至 5 月底超额收益 4%,表现一般, 但整体回撤控制较好。transformer 模型为半年度训练一次,在去年年底训练时, 偏好风格为前 5 年相对较优的小市值等投资策略,无法对今年大盘价值为主的稳 健投资风格进行适应。除了风格控制的因素外,传统模型信号相似,交易拥挤等 原因也可能导致模型近两年策略超额收益下滑。
3.2 stockformer 强化学习模型
我们在论文的基础上,对stockformer模型进行了一定的改进。训练集 验 证集仍然为 6 年,验证集不打乱。在训练时,我们事先训练好三个 transformer 网络,即将三个不同输入的 transformer 模型保存下来,并在强化学习中进行输 入。因为需要考虑到交易费用的问题,我们将由换手率带来的收益衰减增加到了 奖励函数中,以让模型在日度调仓的前提下降低换手率。
最终模型采用滚动每年训练的频率,在测试集上在线(每日)更新策略函数 以输出下一日的交易决策。参数方面,缓冲区 buffer_size 取 107,初始学习率取 3e-4, γ取 0.999,熵正则项初始权重取 0.5,评估频率为每日。学习起始天数 (更新策略函数等)为训练集上第 100 个交易日。sac 强化学习中的演员与评论 家网络均继承了论文中的 transformer 网络。 相对深度学习的单轮训练 epoch 的概念,强化学习从组合的初始状态(学习 起始天数)学习至组合的终止状态,即训练集最后一个交易日,为一集训练 (episode)。我们训练至连续 20 集验证集超额净值无增长作为模型的收敛条件, 每年取验证集表现最好的策略及价值函数模型,进入下一年的在线阶段。
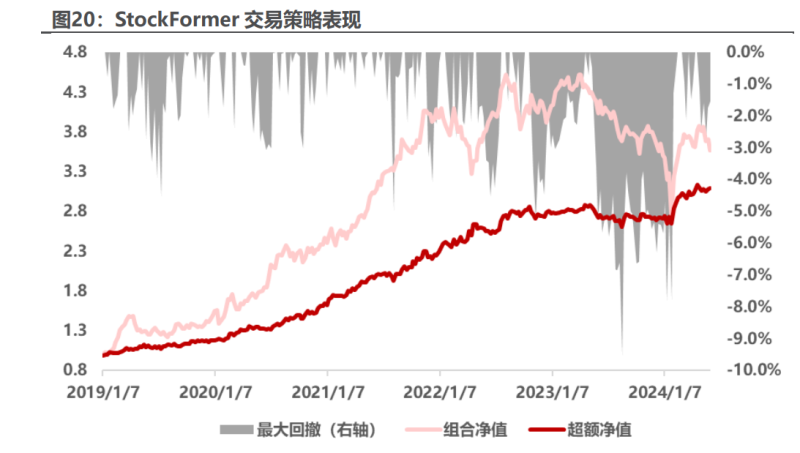
策略年化收益 32.7%,超额收益 29.1%,信息比率 2.57,超额收益波动率 较大,但主要为上行波动,模型总体好于 transformer 的指数增强组合。分年 看策略表现,策略在 2019,2020 年超额收益较高。
回看策略在中证 1000 上的风格因子偏离,可以体现强化学习对于市场主线 的快速识别能力。策略在 2019,2020 年的风格偏离明显,尤其超配了动量和成 长因子,对应了 2020 年的强势风格。在 2022,2023 市场风格主线不明显的行 情下,策略风格偏离快速变换,回到无明显偏离状态,同时也有稳定的超额收益, 体现了强化学习对于市场快速适应的能力。策略今年超额收益优异,超配价值低 波等风格,对市场主线进行了快速识别,体现强化学习的快速适应能力。
强化学习在周度频率上进行学习的表现并不理想,原因可能是训练集内数据 粒度不够细,期数不足导致模型无法充分训练。若我们利用模型的日频仓位进行 周度调仓,效果也会有所衰减,策略年化超额收益 22.6%,信息比率 1.85,超额 收益最大回撤 9.5%,年化双边换手率 58.7 倍。
近年来,深度学习模型如 lstm(长短期记忆网络)和 gru(门控循环单元) 在因子选股方面的表现有所下滑,这现象可能源于多种因素。首先,这些模型在 选股中的广泛应用使得它们的优势逐渐被市场消化和削弱。当越来越多的投资者 使用相似的模型进行选股和交易时,市场中的套利机会变得更加稀缺,模型的边 际效用也随之下降。此外,随着市场环境的不断变化,历史数据可能不再适用于 当前市场情景,导致模型在预测未来表现时的准确性下降。金融市场的动态性要 求模型能够及时适应新的市场条件,而传统深度学习模型为批量训练,难以快速 适应市场的动态变化,导致模型超额收益有所下降。在这种市场环境中,我们未 来的研究将围绕“在线学习”与多样化的“嵌入”为核心,让机器学习模型快速 适应市场变化并理解不同资产中的相关性信息,获得更好的测试集表现。
本篇研究中,我们对于强化学习模型进行了初步尝试,将其与深度学习模型 结合进行组合优化,相比传统因子 优化器的组合构建方式有明显收益提升。强 化学习是一种机器学习方法,通过与环境的交互来训练智能体,使其在不同状态 下采取能够最大化累积奖励的行动。在股票市场中,强化学习可以通过市场状态 的输入,不断调整交易策略,最大化长期的投资回报。本篇研究中我们应用 sac 强化学习作为策略依据。在 sac 中,价值网络是一个双 q 网络(double dqn), 即使用两个独立的 q 网络 同时对目标函数进行估计,在目标值计算时选择最小的 一个,从而降低 q 值的高估风险,防止模型陷入局部最优或者过拟合。此外, sac 在策略优化过程中引入了熵正则化项,通过最大化策略的熵来鼓励探索,还 引入了自适应熵系数α,通过优化熵系数来自动调整策略的探索程度,使得模型 能够根据当前的训练情况动态调整探索与开发的平衡。
stockformer 模型利用 transformer 深度学习进行预测并优化交易决策。 siyu gao 等人在 2023 年 ijcai 上发表的论文 stockformer: learning hybrid trading machines with predictive coding 中采用 sac 强化学习作为基础框架, 并采用了 3 个 transformer 模型分别预测市场相关状态,短期收益状态与长期收 益状态作为强化学习的输入状态。然后在 sac 强化学习中将 3 个隐状态进行合 成,在组合状态空间中优化交易决策。利用沪深 300 成分股做训练,取得了优于 基线 transformer 模型的效果。 深 度 学 习 强 化 学 习 较 深 度 学 习 组 合 优 化 收 益 弹 性 更 高 。 我们将 transformer 模型作为本篇研究中的基模型构建 transformer 因子的指数增强组 合,再与 transformer sac 强化学习算法形成对照。在 transformer 模型中, 我们采用日频行情与 20 个日频技术因子作为输入,预测个股周度收益排序作为 因子,构建的指数增强组合 2019 年以来在中证 1000 内年化收益 17.2%,超额 收益 13.8%,信息比率 2.36,表现稳定。在 stockformer 模型中,我们替换奖 励函数为超额收益-跟踪误差-交易费用,并修改前 3 个 transformer 模型,输出每日交易行为与持仓,策略年化收益 32.7%,超额收益 29.1%,信息比率 2.57, 超额收益波动率较大,但主要为上行波动,模型总体好于 transformer 的指数增 强组合。对策略持仓进行风格分析,发现模型对于市场主线识别能力较强,通过 风格择时带来一定超额收益。 美中不足的是,强化学习在日频的较高频率交易中效果较好,将频率降为周 频会导致时间窗口不足,无法充分训练等问题。未来我们将继续探索以周频甚至 月频为训练环境的框架,通过重复的多次训练,构建较低频率的交易策略。
(本文仅供参考,不代表我们的任何投资建议。如需使用相关信息,请参阅报告原文。)





